A Workflow of Creating Datasets for Multi-modal Machine Learning on Graphs of Heritage Values and Attributes with Social Media
Pre-Print
Authors: Nan Bai, Pirouz Nourian, Renqian Luo, Ana Pereira Roders
Abstract:
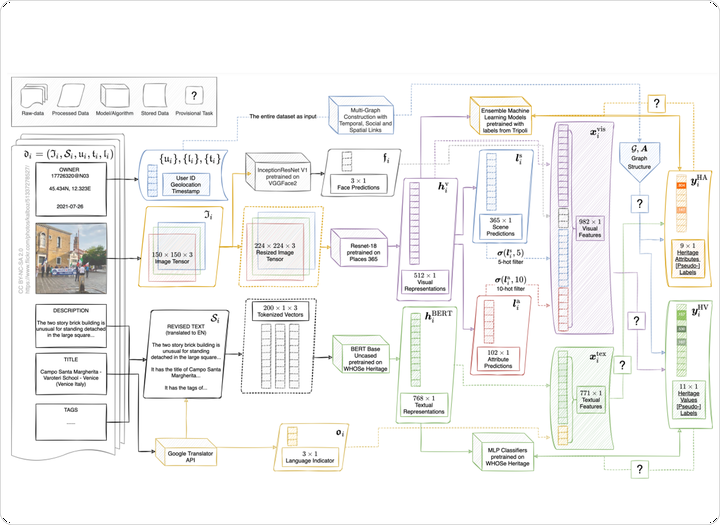
Values (why to conserve) and Attributes (what to conserve) are essential concepts of cultural heritage. Recent studies have been using social media to map values and attributes conveyed by public to cultural heritage. However, it is rare to connect heterogeneous modalities of images, texts, geolocations, timestamps, and social network structures to mine the semantic and structural characteristics therein. This study presents a methodological workflow for constructing such multi-modal datasets using posts and images on Flickr for graph-based machine learning (ML) tasks concerning heritage values and attributes. After data pre-processing using state-of-the-art ML models, the multi-modal information of visual contents and textual semantics are modelled as node features and labels, while their social relationships and spatiotemporal contexts are modelled as links in Multi-Graphs. The workflow is tested in three cities containing UNESCO World Heritage properties - Amsterdam, Suzhou, and Venice, which yielded datasets with high consistency for semi-supervised learning tasks. The entire process is formally described with mathematical notations, ready to be applied in provisional tasks both as ML problems with technical relevance and as urban/heritage study questions with societal interests. This study could also benefit the understanding and mapping of heritage values and attributes for future research in global cases, aiming at inclusive heritage management practices.